Chapter 8 Annotation and visualization
8.1 Adding gene-based annotation
Annotation can be added to a given set of regions using the detailRanges() function.
This will identify overlaps between the regions and annotated genomic features such as exons, introns and promoters.
Here, the promoter region of each gene is defined as some interval 3 kbp up- and 1 kbp downstream of the TSS for that gene.
Any exonic features within dist on the left or right side of each supplied region will also be reported.
#--- loading-files ---#
library(chipseqDBData)
tf.data <- NFYAData()
tf.data
bam.files <- head(tf.data$Path, -1) # skip the input.
bam.files
#--- counting-windows ---#
library(csaw)
frag.len <- 110
win.width <- 10
param <- readParam(minq=20)
data <- windowCounts(bam.files, ext=frag.len, width=win.width, param=param)
#--- filtering ---#
binned <- windowCounts(bam.files, bin=10000, param=param)
fstats <- filterWindowsGlobal(data, binned)
filtered.data <- data[fstats$filter > log2(5),]
#--- normalization ---#
filtered.data <- normFactors(binned, se.out=filtered.data)
#--- modelling ---#
cell.type <- sub("NF-YA ([^ ]+) .*", "\\1", head(tf.data$Description, -1))
design <- model.matrix(~cell.type)
colnames(design) <- c("intercept", "cell.type")
library(edgeR)
y <- asDGEList(filtered.data)
y <- estimateDisp(y, design)
fit <- glmQLFit(y, design, robust=TRUE)
res <- glmQLFTest(fit, coef="cell.type")
rowData(filtered.data) <- cbind(rowData(filtered.data), res$table)
#--- merging ---#
merged <- mergeResults(filtered.data, tol=1000,
merge.args=list(max.width=5000))library(csaw)
library(org.Mm.eg.db)
library(TxDb.Mmusculus.UCSC.mm10.knownGene)
anno <- detailRanges(merged$regions, txdb=TxDb.Mmusculus.UCSC.mm10.knownGene,
orgdb=org.Mm.eg.db, promoter=c(3000, 1000), dist=5000)
head(anno$overlap)## [1] "" "" "Rrs1:+:P,Adhfe1:+:P"
## [4] "Ppp1r42:-:I" "" "Ncoa2:-:PI"## [1] "" "" "" "Ppp1r42:-:3948"
## [5] "" "Ncoa2:-:12"## [1] "" "Rrs1:+:3898"
## [3] "Rrs1:+:48,Adhfe1:+:2588" "Ppp1r42:-:1612"
## [5] "Ncoa2:-:4595" "Ncoa2:-:1278"Character vectors of compact string representations are provided to summarize the features overlapped by each supplied region.
Each pattern contains GENE|STRAND|TYPE to describe the strand and overlapped features of that gene.
Exons are labelled as E, promoters are P and introns are I.
For left and right, TYPE is replaced by DISTANCE.
This indicates the gap (in base pairs) between the supplied region and the closest non-overlapping exon of the annotated feature.
All of this annotation can be stored in the metadata of the GRanges object for later use.
merged$regions$overlap <- anno$overlap
merged$regions$left <- anno$left
merged$regions$right <- anno$rightWhile the string representation saves space in the output, it is not easy to work with.
If the annotation needs to manipulated directly, users can obtain it from the detailRanges() command by not specifying the regions of interest.
This can then be used for interactive manipulation, e.g., to identify all genes where the promoter contains DB sites.
anno.ranges <- detailRanges(txdb=TxDb.Mmusculus.UCSC.mm10.knownGene,
orgdb=org.Mm.eg.db)
anno.ranges## GRanges object with 505738 ranges and 2 metadata columns:
## seqnames ranges strand | symbol type
## <Rle> <IRanges> <Rle> | <character> <character>
## 100009600 chr9 21062393-21062717 - | Zglp1 E
## 100009600 chr9 21062400-21062717 - | Zglp1 E
## 100009600 chr9 21062894-21062987 - | Zglp1 E
## 100009600 chr9 21063314-21063396 - | Zglp1 E
## 100009600 chr9 21066024-21066377 - | Zglp1 E
## ... ... ... ... . ... ...
## 99982 chr4 136554325-136558324 - | Kdm1a P
## 99982 chr4 136560502-136564501 - | Kdm1a P
## 99982 chr4 136567608-136571607 - | Kdm1a P
## 99982 chr4 136576159-136580158 - | Kdm1a P
## 99982 chr4 136550540-136602723 - | Kdm1a G
## -------
## seqinfo: 66 sequences (1 circular) from mm10 genome8.2 Checking bimodality for TF studies
For TF experiments, a simple measure of strand bimodality can be reported as a diagnostic.
Given a set of regions, the checkBimodality() function will return the maximum bimodality score across all base positions in each region.
The bimodality score at each base position is defined as the minimum of the ratio of the number of forward- to reverse-stranded reads to the left of that position, and the ratio of the reverse- to forward-stranded reads to the right.
A high score is only possible if both ratios are large, i.e., strand bimodality is present.
# TODO: make this less weird.
spacing <- metadata(data)$spacing
expanded <- resize(merged$regions, fix="center",
width=width(merged$regions)+spacing)
sbm.score <- checkBimodality(bam.files, expanded, width=frag.len)
head(sbm.score)## [1] 1.456 2.263 1.364 5.333 1.933 3.405In the above code, all regions are expanded by spacing, i.e., 50 bp.
This ensures that the optimal bimodality score can be computed for the centre of the binding site, even if that position is not captured by a window.
The width argument specifies the span with which to count reads for the score calculation.
This should be set to the average fragment length.
If multiple bam.files are provided, they will be pooled during counting.
For typical TF binding sites, bimodality scores can be considered to be “high” if they are larger than 4. This allows users to distinguish between genuine binding sites and high-abundance artifacts such as repeats or read stacks. However, caution is still required as some high scores may be driven by the stochastic distribution of reads. Obviously, the concept of strand bimodality is less relevant for diffuse targets like histone marks.
8.3 Saving the results to file
It is a simple matter to save the results for later perusal, e.g., to a tab-separated file.
ofile <- gzfile("clusters.tsv.gz", open="w")
write.table(as.data.frame(merged), file=ofile,
row.names=FALSE, quote=FALSE, sep="\t")
close(ofile)Of course, other formats can be used depending on the purpose of the file. For example, significantly DB regions can be exported to BED files through the rtracklayer package for visual inspection with genomic browsers. A transformed FDR is used here for the score field.
is.sig <- merged$combined$FDR <= 0.05
test <- merged$regions[is.sig]
test$score <- -10*log10(merged$combined$FDR[is.sig])
names(test) <- paste0("region", 1:sum(is.sig))
library(rtracklayer)
export(test, "clusters.bed")
head(read.table("clusters.bed"))## V1 V2 V3 V4 V5 V6
## 1 chr1 7397900 7398110 region1 14.63 .
## 2 chr1 9541400 9541510 region2 16.61 .
## 3 chr1 9545300 9545360 region3 13.36 .
## 4 chr1 13589950 13590010 region4 15.36 .
## 5 chr1 15805500 15805660 region5 24.05 .
## 6 chr1 16657100 16657160 region6 13.61 .Alternatively, the GRanges object can be directly saved to file and reloaded later for direct manipulation in the R environment, e.g., to find overlaps with other regions of interest.
8.4 Simple visualization of genomic coverage
Visualization of the read depth around interesting features is often desired.
This is facilitated by the extractReads() function, which pulls out the reads from the BAM file.
The returned GRanges object can then be used to plot the sequencing coverage or any other statistic of interest.
Note that the extractReads() function also accepts a readParam object.
This ensures that the same reads used in the analysis will be pulled out during visualization.
cur.region <- GRanges("chr18", IRanges(77806807, 77807165))
extractReads(bam.files[[1]], cur.region, param=param)## GRanges object with 55 ranges and 0 metadata columns:
## seqnames ranges strand
## <Rle> <IRanges> <Rle>
## [1] chr18 77806886-77806922 +
## [2] chr18 77806887-77806923 +
## [3] chr18 77806887-77806923 +
## [4] chr18 77806887-77806923 +
## [5] chr18 77806890-77806926 +
## ... ... ... ...
## [51] chr18 77807063-77807095 -
## [52] chr18 77807068-77807104 -
## [53] chr18 77807082-77807119 -
## [54] chr18 77807084-77807120 -
## [55] chr18 77807087-77807123 -
## -------
## seqinfo: 1 sequence from an unspecified genomeHere, coverage is visualized as the number of reads covering each base pair in the interval of interest. Specifically, the reads-per-million is shown to allow comparisons between libraries of different size. The plots themselves are constructed using methods from the Gviz package. The blue and red tracks represent the coverage on the forward and reverse strands, respectively. Strong strand bimodality is consistent with a genuine TF binding site. For paired-end data, coverage can be similarly plotted for fragments, i.e., proper read pairs.
library(Gviz)
collected <- vector("list", length(bam.files))
for (i in seq_along(bam.files)) {
reads <- extractReads(bam.files[[i]], cur.region, param=param)
adj.total <- data$totals[i]/1e6
pcov <- as(coverage(reads[strand(reads)=="+"])/adj.total, "GRanges")
ncov <- as(coverage(reads[strand(reads)=="-"])/adj.total, "GRanges")
ptrack <- DataTrack(pcov, type="histogram", lwd=0, fill=rgb(0,0,1,.4),
ylim=c(0,1.1), name=tf.data$Name[i], col.axis="black",
col.title="black")
ntrack <- DataTrack(ncov, type="histogram", lwd=0, fill=rgb(1,0,0,.4),
ylim=c(0,1.1))
collected[[i]] <- OverlayTrack(trackList=list(ptrack,ntrack))
}
gax <- GenomeAxisTrack(col="black")
plotTracks(c(gax, collected), from=start(cur.region), to=end(cur.region))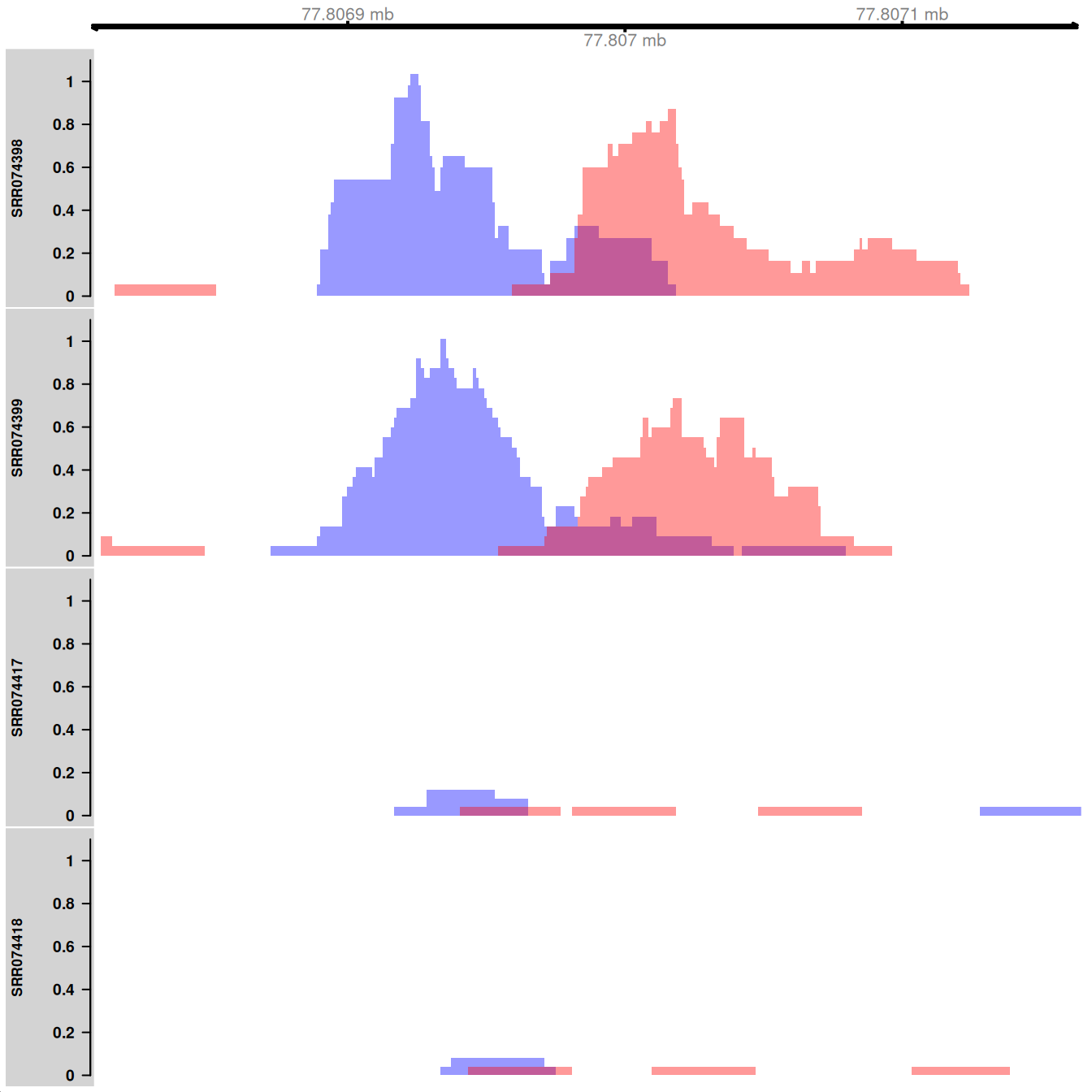
Session information
R version 4.5.0 RC (2025-04-04 r88126)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.2 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.21-bioc/R/lib/libRblas.so
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.12.0 LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] Gviz_1.52.0
[2] rtracklayer_1.68.0
[3] TxDb.Mmusculus.UCSC.mm10.knownGene_3.10.0
[4] GenomicFeatures_1.60.0
[5] org.Mm.eg.db_3.21.0
[6] AnnotationDbi_1.70.0
[7] csaw_1.42.0
[8] SummarizedExperiment_1.38.0
[9] Biobase_2.68.0
[10] MatrixGenerics_1.20.0
[11] matrixStats_1.5.0
[12] GenomicRanges_1.60.0
[13] GenomeInfoDb_1.44.0
[14] IRanges_2.42.0
[15] S4Vectors_0.46.0
[16] BiocGenerics_0.54.0
[17] generics_0.1.3
[18] BiocStyle_2.36.0
[19] rebook_1.18.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 rstudioapi_0.17.1 jsonlite_2.0.0
[4] CodeDepends_0.6.6 magrittr_2.0.3 rmarkdown_2.29
[7] BiocIO_1.18.0 vctrs_0.6.5 memoise_2.0.1
[10] Rsamtools_2.24.0 RCurl_1.98-1.17 base64enc_0.1-3
[13] htmltools_0.5.8.1 S4Arrays_1.8.0 progress_1.2.3
[16] curl_6.2.2 SparseArray_1.8.0 Formula_1.2-5
[19] sass_0.4.10 bslib_0.9.0 htmlwidgets_1.6.4
[22] httr2_1.1.2 cachem_1.1.0 GenomicAlignments_1.44.0
[25] lifecycle_1.0.4 pkgconfig_2.0.3 Matrix_1.7-3
[28] R6_2.6.1 fastmap_1.2.0 GenomeInfoDbData_1.2.14
[31] digest_0.6.37 colorspace_2.1-1 Hmisc_5.2-3
[34] RSQLite_2.3.9 filelock_1.0.3 httr_1.4.7
[37] abind_1.4-8 compiler_4.5.0 bit64_4.6.0-1
[40] htmlTable_2.4.3 backports_1.5.0 BiocParallel_1.42.0
[43] DBI_1.2.3 biomaRt_2.64.0 rappdirs_0.3.3
[46] DelayedArray_0.34.0 rjson_0.2.23 tools_4.5.0
[49] foreign_0.8-90 nnet_7.3-20 glue_1.8.0
[52] restfulr_0.0.15 checkmate_2.3.2 cluster_2.1.8.1
[55] gtable_0.3.6 BSgenome_1.76.0 ensembldb_2.32.0
[58] data.table_1.17.0 hms_1.1.3 metapod_1.16.0
[61] xml2_1.3.8 XVector_0.48.0 pillar_1.10.2
[64] stringr_1.5.1 limma_3.64.0 dplyr_1.1.4
[67] BiocFileCache_2.16.0 lattice_0.22-7 deldir_2.0-4
[70] bit_4.6.0 biovizBase_1.56.0 tidyselect_1.2.1
[73] locfit_1.5-9.12 Biostrings_2.76.0 knitr_1.50
[76] gridExtra_2.3 bookdown_0.43 ProtGenerics_1.40.0
[79] edgeR_4.6.0 xfun_0.52 statmod_1.5.0
[82] stringi_1.8.7 UCSC.utils_1.4.0 lazyeval_0.2.2
[85] yaml_2.3.10 evaluate_1.0.3 codetools_0.2-20
[88] interp_1.1-6 tibble_3.2.1 BiocManager_1.30.25
[91] graph_1.86.0 cli_3.6.4 rpart_4.1.24
[94] munsell_0.5.1 jquerylib_0.1.4 dichromat_2.0-0.1
[97] Rcpp_1.0.14 dir.expiry_1.16.0 dbplyr_2.5.0
[100] png_0.1-8 XML_3.99-0.18 parallel_4.5.0
[103] ggplot2_3.5.2 blob_1.2.4 prettyunits_1.2.0
[106] jpeg_0.1-11 latticeExtra_0.6-30 AnnotationFilter_1.32.0
[109] bitops_1.0-9 VariantAnnotation_1.54.0 scales_1.3.0
[112] crayon_1.5.3 rlang_1.1.6 KEGGREST_1.48.0