Chapter 11 Single-nuclei RNA-seq processing
11.1 Introduction
Single-nuclei RNA-seq (snRNA-seq) provides another strategy for performing single-cell transcriptomics where individual nuclei instead of cells are captured and sequenced. The major advantage of snRNA-seq over scRNA-seq is that the former does not require the preservation of cellular integrity during sample preparation, especially dissociation. We only need to extract nuclei in an intact state, meaning that snRNA-seq can be applied to cell types, tissues and samples that are not amenable to dissociation and later processing. The cost of this flexibility is the loss of transcripts that are primarily located in the cytoplasm, potentially limiting the availability of biological signal for genes with little nuclear localization.
The computational analysis of snRNA-seq data is very much like that of scRNA-seq data. We have a matrix of (UMI) counts for genes by cells that requires quality control, normalization and so on. (Technically, the columsn correspond to nuclei but we will use these two terms interchangeably in this chapter.) In fact, the biggest difference in processing occurs in the construction of the count matrix itself, where intronic regions must be included in the annotation for each gene to account for the increased abundance of unspliced transcripts. The rest of the analysis only requires a few minor adjustments to account for the loss of cytoplasmic transcripts. We demonstrate using a dataset from Wu et al. (2019) involving snRNA-seq on healthy and fibrotic mouse kidneys.
## class: SingleCellExperiment
## dim: 18249 8231
## metadata(0):
## assays(1): counts
## rownames(18249): mt-Cytb mt-Nd6 ... Gm44613 Gm38304
## rowData names(0):
## colnames: NULL
## colData names(4): CellBarcode CellType Technology Status
## reducedDimNames(0):
## mainExpName: NULL
## altExpNames(0):11.2 Quality control for stripped nuclei
The loss of the cytoplasm means that the stripped nuclei should not contain any mitochondrial transcripts. This means that the mitochondrial proportion becomes an excellent QC metric for the efficacy of the stripping process. Unlike scRNA-seq, there is no need to worry about variations in mitochondrial content due to genuine biology. High-quality nuclei should not contain any mitochondrial transcripts; the presence of any mitochondrial counts in a library indicates that the removal of the cytoplasm was not complete, possibly introducing irrelevant heterogeneity in downstream analyses.
library(scuttle)
sce <- addPerCellQC(sce, subsets=list(Mt=grep("^mt-", rownames(sce))))
summary(sce$subsets_Mt_percent == 0)## Mode FALSE TRUE
## logical 2264 5967We apply a simple filter to remove libraries corresponding to incompletely stripped nuclei. The outlier-based approach described in Section 12.3 can be used here, but some caution is required in low-coverage experiments where a majority of cells have zero mitochondrial counts. In such cases, the MAD may also be zero such that other libraries with very low but non-zero mitochondrial counts are removed. This is typically too conservative as such transcripts may be present due to sporadic ambient contamination rather than incomplete stripping.
## low_lib_size low_n_features high_subsets_Mt_percent
## 0 0 2264
## discard
## 2264Instead, we enforce a minimum difference between the threshold and the median in isOutlier() (Figure 11.1).
We arbitrarily choose +0.5% here, which takes precedence over the outlier-based threshold if the latter is too low.
In this manner, we avoid discarding libraries with a very modest amount of contamination; the same code will automatically fall back to the outlier-based threshold in datasets where the stripping was systematically less effective.
stats$high_subsets_Mt_percent <- isOutlier(sce$subsets_Mt_percent,
type="higher", min.diff=0.5)
stats$discard <- Reduce("|", stats[,colnames(stats)!="discard"])
colSums(as.matrix(stats))## low_lib_size low_n_features high_subsets_Mt_percent
## 0 0 42
## discard
## 42library(scater)
plotColData(sce, x="Status", y="subsets_Mt_percent",
colour_by=I(stats$high_subsets_Mt_percent))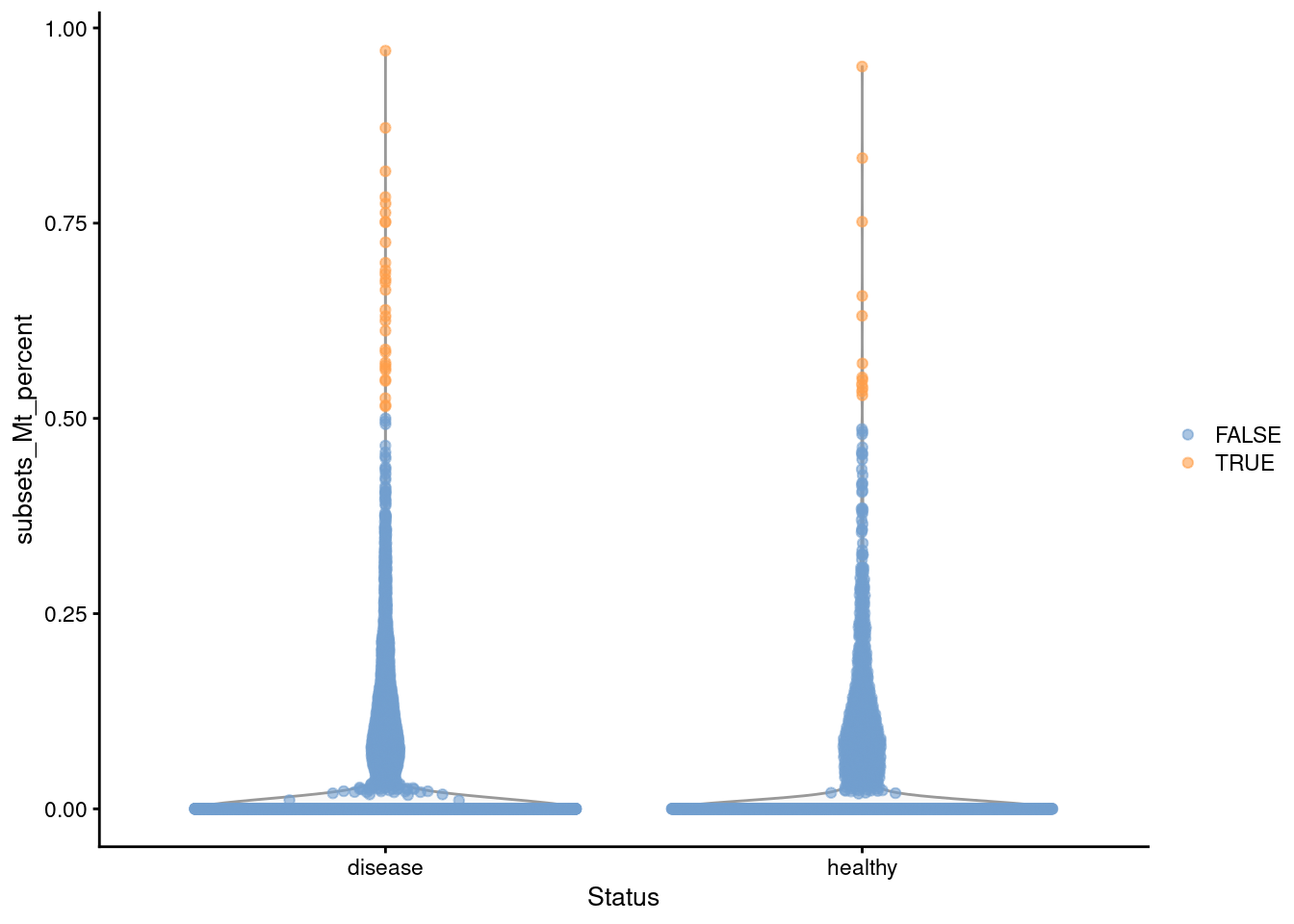
Figure 11.1: Distribution of the mitochondrial proportions in the Wu kidney dataset. Each point represents a cell and is colored according to whether it was considered to be of low quality and discarded.
11.4 Tricks with ambient contamination
The expected absence of genuine mitochondrial expression can also be exploited to estimate the level of ambient contamination (Multi-sample Chapter 5). We demonstrate on mouse brain snRNA-seq data from 10X Genomics (Zheng et al. 2017), using the raw count matrix prior to any filtering for nuclei-containing barcodes.
library(DropletTestFiles)
raw.path <- getTestFile("tenx-2.0.1-nuclei_900/1.0.0/raw.tar.gz")
out.path <- file.path(tempdir(), "nuclei")
untar(raw.path, exdir=out.path)
library(DropletUtils)
fname <- file.path(out.path, "raw_gene_bc_matrices/mm10")
sce.brain <- read10xCounts(fname, col.names=TRUE)
sce.brain## class: SingleCellExperiment
## dim: 27998 737280
## metadata(1): Samples
## assays(1): counts
## rownames(27998): ENSMUSG00000051951 ENSMUSG00000089699 ...
## ENSMUSG00000096730 ENSMUSG00000095742
## rowData names(2): ID Symbol
## colnames(737280): AAACCTGAGAAACCAT-1 AAACCTGAGAAACCGC-1 ...
## TTTGTCATCTTTAGTC-1 TTTGTCATCTTTCCTC-1
## colData names(2): Sample Barcode
## reducedDimNames(0):
## mainExpName: NULL
## altExpNames(0):We call non-empty droplets using emptyDrops() as previously described (Section 7.2).
## Mode FALSE TRUE NA's
## logical 2282 1754 733244If our libraries are of high quality, we can assume that any mitochondrial “expression” is due to contamination from the ambient solution.
We then use the controlAmbience() function to estimate the proportion of ambient contamination for each gene, allowing us to mark potentially problematic genes in the DE results (Figure 11.4).
In fact, we can use this information even earlier to remove these genes during dimensionality reduction and clustering.
This is not generally possible for scRNA-seq as any notable contaminating transcripts may originate from a subpopulation that actually expresses that gene and thus cannot be blindly removed.
ambient <- estimateAmbience(counts(sce.brain), round=FALSE, good.turing=FALSE)
nuclei <- rowSums(counts(sce.brain)[,which(e.out$FDR <= 0.001)])
is.mito <- grepl("mt-", rowData(sce.brain)$Symbol)
contam <- controlAmbience(nuclei, ambient, features=is.mito, mode="proportion")
plot(log10(nuclei+1), contam*100, col=ifelse(is.mito, "red", "grey"), pch=16,
xlab="Log-nuclei expression", ylab="Contamination (%)")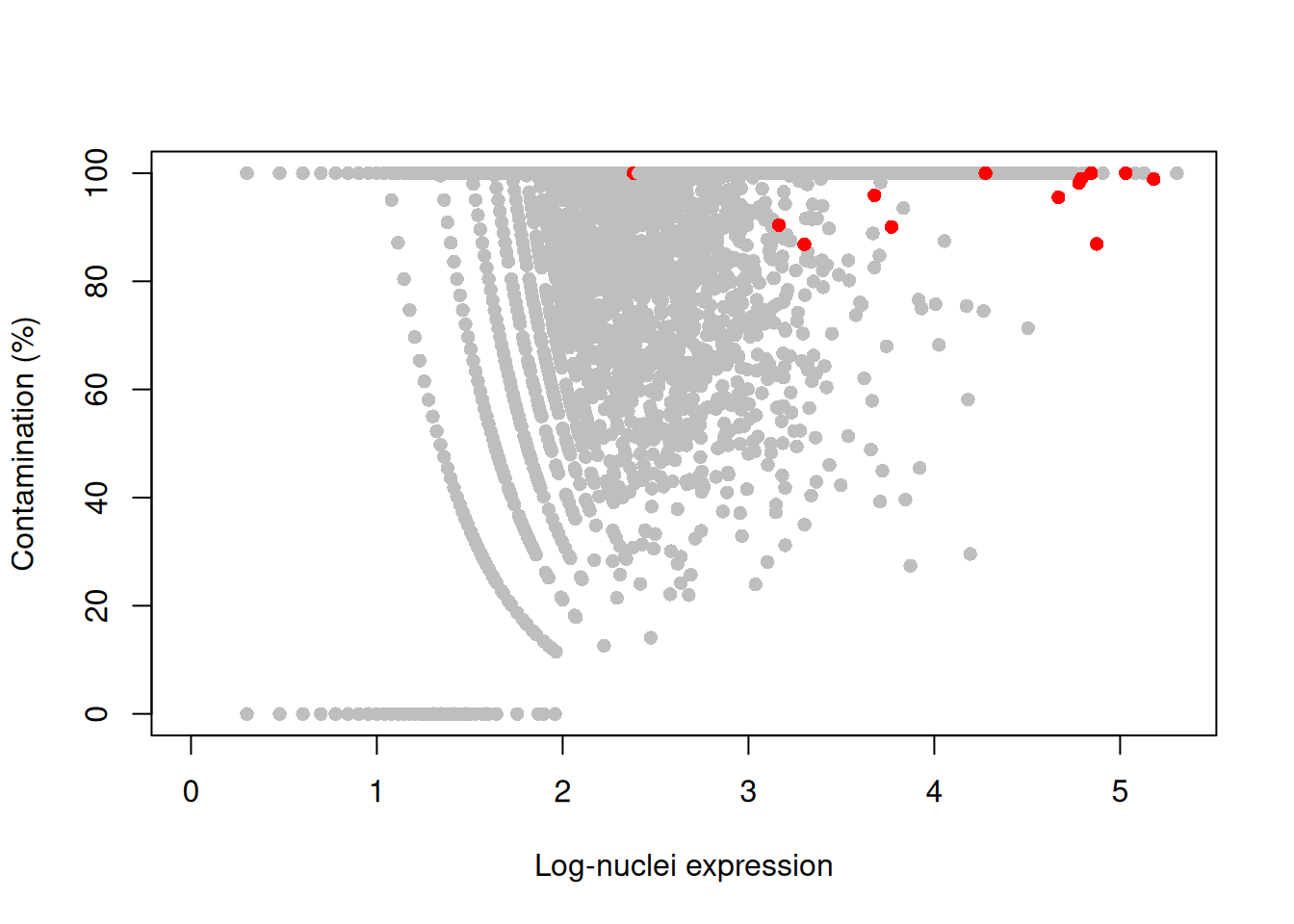
Figure 11.4: Percentage of counts in the nuclei of the 10X brain dataset that are attributed to contamination from the ambient solution. Each point represents a gene and mitochondrial genes are highlighted in red.
Session Info
R version 4.5.1 (2025-06-13)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.3 LTS
Matrix products: default
BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] DropletUtils_1.29.4 DropletTestFiles_1.19.0
[3] batchelor_1.25.0 bluster_1.19.0
[5] scran_1.37.0 scater_1.37.0
[7] ggplot2_3.5.2 scuttle_1.19.0
[9] scRNAseq_2.23.0 SingleCellExperiment_1.31.1
[11] SummarizedExperiment_1.39.1 Biobase_2.69.0
[13] GenomicRanges_1.61.1 Seqinfo_0.99.2
[15] IRanges_2.43.0 S4Vectors_0.47.0
[17] BiocGenerics_0.55.1 generics_0.1.4
[19] MatrixGenerics_1.21.0 matrixStats_1.5.0
[21] BiocStyle_2.37.1 rebook_1.19.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_2.0.0
[3] CodeDepends_0.6.6 magrittr_2.0.3
[5] ggbeeswarm_0.7.2 GenomicFeatures_1.61.6
[7] gypsum_1.5.0 farver_2.1.2
[9] rmarkdown_2.29 BiocIO_1.19.0
[11] vctrs_0.6.5 DelayedMatrixStats_1.31.0
[13] memoise_2.0.1 Rsamtools_2.25.2
[15] RCurl_1.98-1.17 htmltools_0.5.8.1
[17] S4Arrays_1.9.1 AnnotationHub_3.99.6
[19] curl_6.4.0 BiocNeighbors_2.3.1
[21] Rhdf5lib_1.31.0 SparseArray_1.9.1
[23] rhdf5_2.53.4 sass_0.4.10
[25] alabaster.base_1.9.5 bslib_0.9.0
[27] alabaster.sce_1.9.0 httr2_1.2.1
[29] cachem_1.1.0 ResidualMatrix_1.19.0
[31] GenomicAlignments_1.45.2 igraph_2.1.4
[33] lifecycle_1.0.4 pkgconfig_2.0.3
[35] rsvd_1.0.5 Matrix_1.7-3
[37] R6_2.6.1 fastmap_1.2.0
[39] digest_0.6.37 AnnotationDbi_1.71.1
[41] dqrng_0.4.1 irlba_2.3.5.1
[43] ExperimentHub_2.99.5 RSQLite_2.4.2
[45] beachmat_2.25.4 labeling_0.4.3
[47] filelock_1.0.3 httr_1.4.7
[49] abind_1.4-8 compiler_4.5.1
[51] bit64_4.6.0-1 withr_3.0.2
[53] BiocParallel_1.43.4 viridis_0.6.5
[55] DBI_1.2.3 R.utils_2.13.0
[57] HDF5Array_1.37.0 alabaster.ranges_1.9.1
[59] alabaster.schemas_1.9.0 rappdirs_0.3.3
[61] DelayedArray_0.35.2 rjson_0.2.23
[63] tools_4.5.1 vipor_0.4.7
[65] beeswarm_0.4.0 R.oo_1.27.1
[67] glue_1.8.0 h5mread_1.1.1
[69] restfulr_0.0.16 rhdf5filters_1.21.0
[71] grid_4.5.1 Rtsne_0.17
[73] cluster_2.1.8.1 gtable_0.3.6
[75] R.methodsS3_1.8.2 ensembldb_2.33.1
[77] metapod_1.17.0 BiocSingular_1.25.0
[79] ScaledMatrix_1.17.0 XVector_0.49.0
[81] ggrepel_0.9.6 BiocVersion_3.22.0
[83] pillar_1.11.0 limma_3.65.3
[85] dplyr_1.1.4 BiocFileCache_2.99.5
[87] lattice_0.22-7 rtracklayer_1.69.1
[89] bit_4.6.0 tidyselect_1.2.1
[91] locfit_1.5-9.12 Biostrings_2.77.2
[93] knitr_1.50 gridExtra_2.3
[95] bookdown_0.43 ProtGenerics_1.41.0
[97] edgeR_4.7.3 xfun_0.52
[99] statmod_1.5.0 UCSC.utils_1.5.0
[101] lazyeval_0.2.2 yaml_2.3.10
[103] evaluate_1.0.4 codetools_0.2-20
[105] tibble_3.3.0 alabaster.matrix_1.9.0
[107] BiocManager_1.30.26 graph_1.87.0
[109] cli_3.6.5 jquerylib_0.1.4
[111] dichromat_2.0-0.1 Rcpp_1.1.0
[113] GenomeInfoDb_1.45.9 dir.expiry_1.17.0
[115] dbplyr_2.5.0 png_0.1-8
[117] XML_3.99-0.18 parallel_4.5.1
[119] blob_1.2.4 AnnotationFilter_1.33.0
[121] sparseMatrixStats_1.21.0 bitops_1.0-9
[123] alabaster.se_1.9.0 viridisLite_0.4.2
[125] scales_1.4.0 purrr_1.1.0
[127] crayon_1.5.3 rlang_1.1.6
[129] cowplot_1.2.0 KEGGREST_1.49.1 References
Bakken, T. E., R. D. Hodge, J. A. Miller, Z. Yao, T. N. Nguyen, B. Aevermann, E. Barkan, et al. 2018. “Single-nucleus and single-cell transcriptomes compared in matched cortical cell types.” PLoS ONE 13 (12): e0209648.
Wu, H., Y. Kirita, E. L. Donnelly, and B. D. Humphreys. 2019. “Advantages of Single-Nucleus over Single-Cell RNA Sequencing of Adult Kidney: Rare Cell Types and Novel Cell States Revealed in Fibrosis.” J. Am. Soc. Nephrol. 30 (1): 23–32.
Zheng, G. X., J. M. Terry, P. Belgrader, P. Ryvkin, Z. W. Bent, R. Wilson, S. B. Ziraldo, et al. 2017. “Massively parallel digital transcriptional profiling of single cells.” Nat Commun 8 (January): 14049.
11.3 Comments on downstream analyses
The rest of the analysis can then be performed using the same strategies discussed for scRNA-seq (Figure 11.2). Despite the loss of cytoplasmic transcripts, there is usually still enough biological signal to characterize population heterogeneity (Bakken et al. 2018; Wu et al. 2019). In fact, one could even say that snRNA-seq has a higher signal-to-noise ratio as sequencing coverage is not spent on highly abundant but typically uninteresting transcripts for mitochondrial and ribosomal protein genes. It also has the not inconsiderable advantage of being able to recover subpopulations that are not amenable to dissociation and would be lost by scRNA-seq protocols.
Figure 11.2: \(t\)-SNE plots of the Wu kidney dataset. Each point is a cell and is colored by its cluster assignment (left) or its disease status (right).
We can also apply more complex procedures such as batch correction (Multi-sample Chapter 1). Here, we eliminate the disease effect to identify shared clusters (Figure 11.3).
Figure 11.3: More \(t\)-SNE plots of the Wu kidney dataset after applying MNN correction across diseases.
Similarly, we can perform marker detection on the snRNA-seq expression values as discussed in Basic Chapter 6. For the most part, interpretation of these DE results makes the simplifying assumption that nuclear abundances are a good proxy for the overall expression profile. This is generally reasonable but may not always be true, resulting in some discrepancies in the marker sets between snRNA-seq and scRNA-seq datasets. For example, transcripts for strongly expressed genes might localize to the cytoplasm for efficient translation and subsequently be lost upon stripping, while genes with the same overall expression but differences in the rate of nuclear export may appear to be differentially expressed between clusters. In the most pathological case, higher snRNA-seq abundances may indicate nuclear sequestration of transcripts for protein-coding genes and reduced activity of the relevant biological process, contrary to the usual interpretation of the effect of upregulation.
Other analyses described for scRNA-seq require more care when they are applied to snRNA-seq data. Most obviously, cell type annotation based on reference profiles (Basic Chapter 7) should be treated with some caution as the majority of existing references are constructed from bulk or single-cell datasets with cytoplasmic transcripts. Interpretation of RNA velocity results may also be complicated by variation in the rate of nuclear export of spliced transcripts.