Chapter 5 Grun human pancreas (CEL-seq2)
5.1 Introduction
This workflow performs an analysis of the Grun et al. (2016) CEL-seq2 dataset consisting of human pancreas cells from various donors.
5.2 Data loading
We convert to Ensembl identifiers, and we remove duplicated genes or genes without Ensembl IDs.
5.3 Quality control
This dataset lacks mitochondrial genes so we will do without them for quality control.
We compute the median and MAD while blocking on the donor;
for donors where the assumption of a majority of high-quality cells seems to be violated (Figure 5.1),
we compute an appropriate threshold using the other donors as specified in the subset= argument.
library(scater)
stats <- perCellQCMetrics(sce.grun)
qc <- quickPerCellQC(stats, percent_subsets="altexps_ERCC_percent",
batch=sce.grun$donor,
subset=sce.grun$donor %in% c("D17", "D7", "D2"))
sce.grun <- sce.grun[,!qc$discard]colData(unfiltered) <- cbind(colData(unfiltered), stats)
unfiltered$discard <- qc$discard
gridExtra::grid.arrange(
plotColData(unfiltered, x="donor", y="sum", colour_by="discard") +
scale_y_log10() + ggtitle("Total count"),
plotColData(unfiltered, x="donor", y="detected", colour_by="discard") +
scale_y_log10() + ggtitle("Detected features"),
plotColData(unfiltered, x="donor", y="altexps_ERCC_percent",
colour_by="discard") + ggtitle("ERCC percent"),
ncol=2
)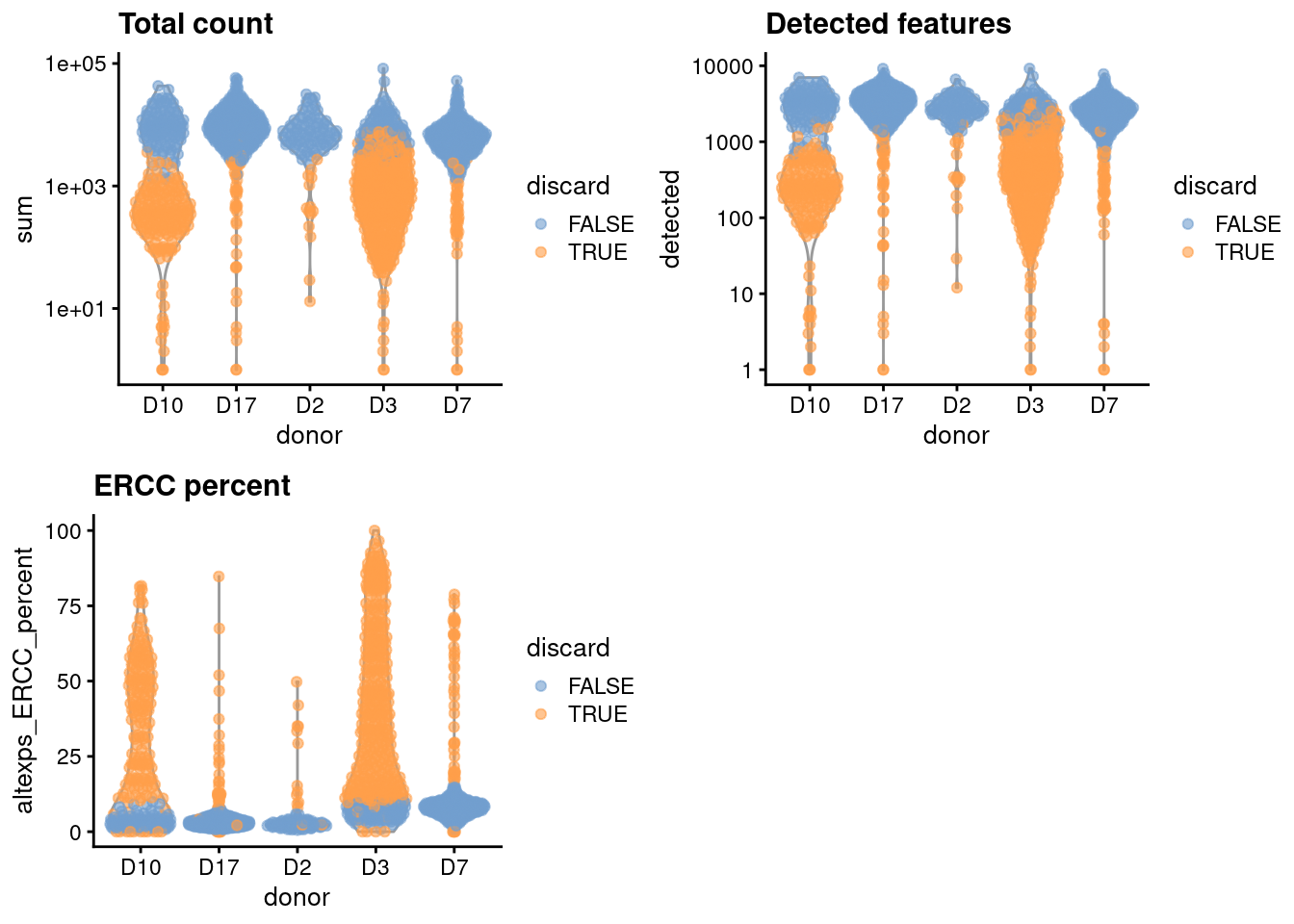
Figure 5.1: Distribution of each QC metric across cells from each donor of the Grun pancreas dataset. Each point represents a cell and is colored according to whether that cell was discarded.
## low_lib_size low_n_features high_altexps_ERCC_percent
## 450 511 606
## discard
## 6655.4 Normalization
library(scran)
set.seed(1000) # for irlba.
clusters <- quickCluster(sce.grun)
sce.grun <- computeSumFactors(sce.grun, clusters=clusters)
sce.grun <- logNormCounts(sce.grun)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.095 0.508 0.795 1.000 1.226 12.017plot(librarySizeFactors(sce.grun), sizeFactors(sce.grun), pch=16,
xlab="Library size factors", ylab="Deconvolution factors", log="xy")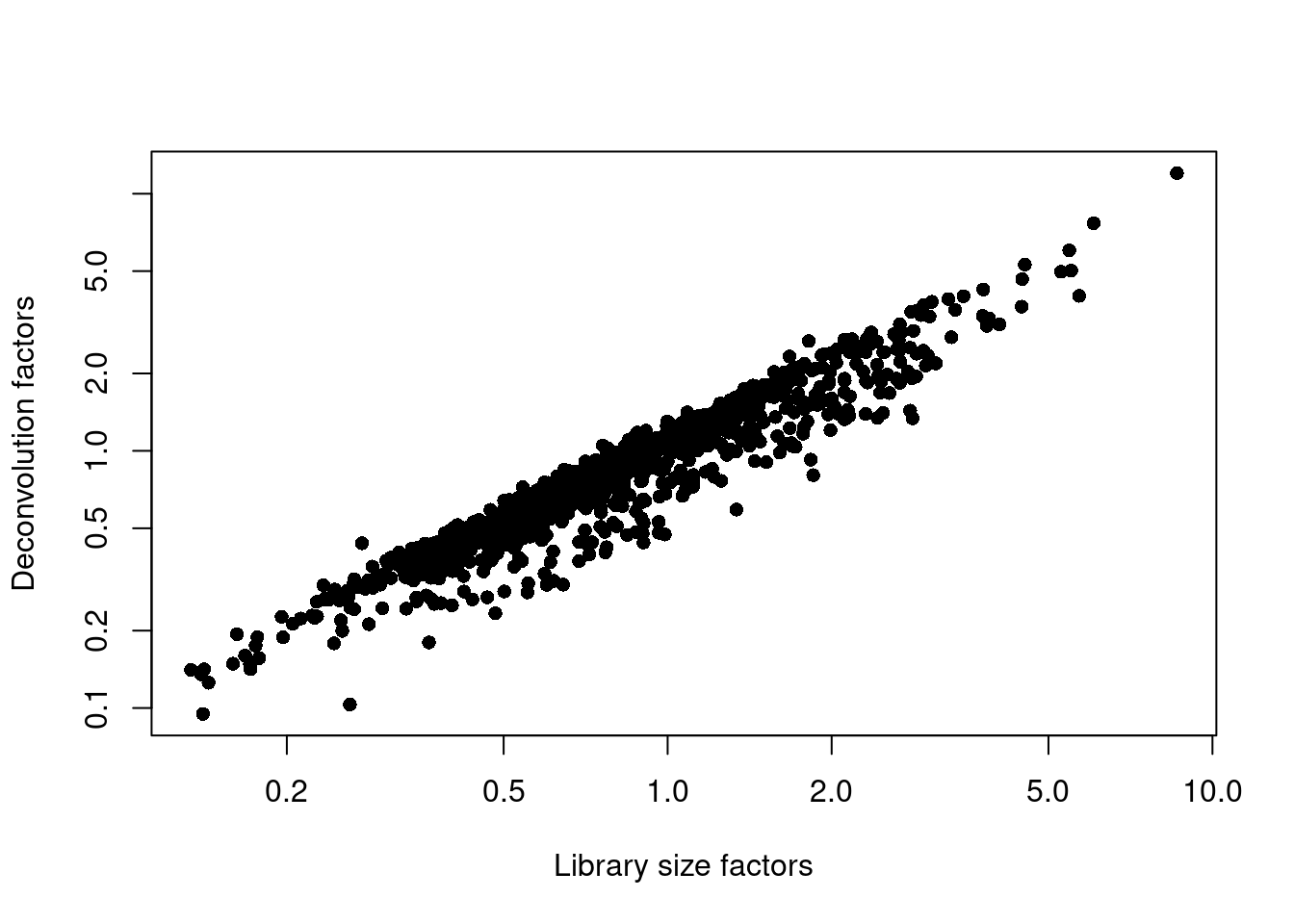
Figure 5.2: Relationship between the library size factors and the deconvolution size factors in the Grun pancreas dataset.
5.5 Variance modelling
We block on a combined plate and donor factor.
block <- paste0(sce.grun$sample, "_", sce.grun$donor)
dec.grun <- modelGeneVarWithSpikes(sce.grun, spikes="ERCC", block=block)
top.grun <- getTopHVGs(dec.grun, prop=0.1)We examine the number of cells in each level of the blocking factor.
## block
## CD13+ sorted cells_D17 CD24+ CD44+ live sorted cells_D17
## 86 87
## CD63+ sorted cells_D10 TGFBR3+ sorted cells_D17
## 41 90
## exocrine fraction, live sorted cells_D2 exocrine fraction, live sorted cells_D3
## 82 7
## live sorted cells, library 1_D10 live sorted cells, library 1_D17
## 33 88
## live sorted cells, library 1_D3 live sorted cells, library 1_D7
## 24 85
## live sorted cells, library 2_D10 live sorted cells, library 2_D17
## 35 83
## live sorted cells, library 2_D3 live sorted cells, library 2_D7
## 27 84
## live sorted cells, library 3_D3 live sorted cells, library 3_D7
## 16 83
## live sorted cells, library 4_D3 live sorted cells, library 4_D7
## 29 83par(mfrow=c(6,3))
blocked.stats <- dec.grun$per.block
for (i in colnames(blocked.stats)) {
current <- blocked.stats[[i]]
plot(current$mean, current$total, main=i, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curfit <- metadata(current)
points(curfit$mean, curfit$var, col="red", pch=16)
curve(curfit$trend(x), col='dodgerblue', add=TRUE, lwd=2)
}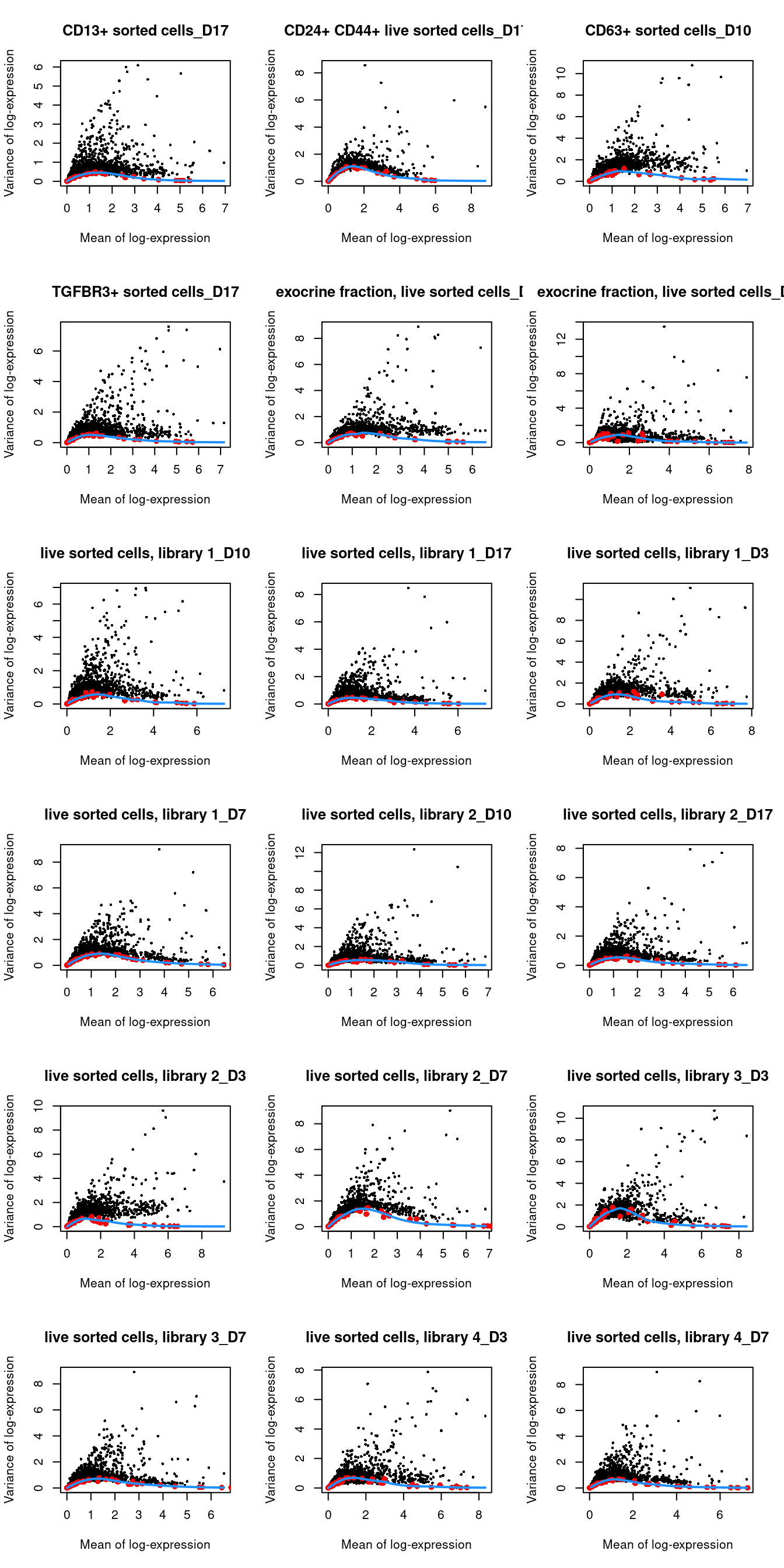
Figure 1.4: Per-gene variance as a function of the mean for the log-expression values in the Grun pancreas dataset. Each point represents a gene (black) with the mean-variance trend (blue) fitted to the spike-in transcripts (red) separately for each donor.
5.6 Data integration
library(batchelor)
set.seed(1001010)
merged.grun <- fastMNN(sce.grun, subset.row=top.grun, batch=sce.grun$donor)## D10 D17 D2 D3 D7
## [1,] 0.030870 0.030495 0.000000 0.00000 0.00000
## [2,] 0.006748 0.011027 0.037205 0.00000 0.00000
## [3,] 0.003823 0.005436 0.007584 0.05033 0.00000
## [4,] 0.012041 0.014283 0.013917 0.01297 0.052885.7 Dimensionality reduction
5.8 Clustering
snn.gr <- buildSNNGraph(merged.grun, use.dimred="corrected")
colLabels(merged.grun) <- factor(igraph::cluster_walktrap(snn.gr)$membership)## Donor
## Cluster D10 D17 D2 D3 D7
## 1 17 73 3 2 77
## 2 7 12 5 7 8
## 3 12 128 0 0 62
## 4 27 107 43 13 116
## 5 32 70 31 80 28
## 6 5 13 0 0 10
## 7 5 18 0 1 33
## 8 4 13 0 0 1gridExtra::grid.arrange(
plotTSNE(merged.grun, colour_by="label"),
plotTSNE(merged.grun, colour_by="batch"),
ncol=2
)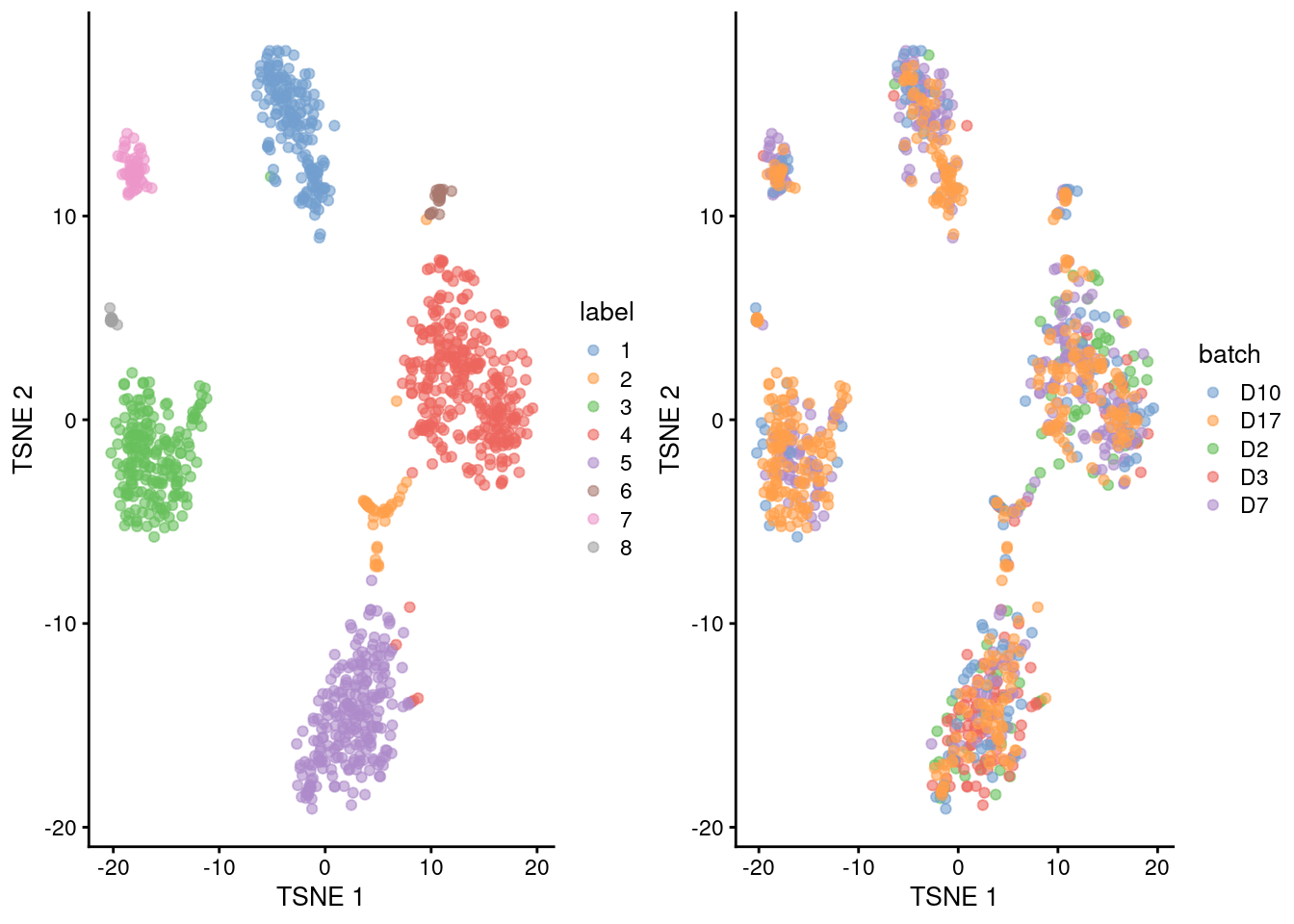
Figure 5.3: Obligatory \(t\)-SNE plots of the Grun pancreas dataset. Each point represents a cell that is colored by cluster (left) or batch (right).
Session Info
R version 4.1.0 (2021-05-18)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.2 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.13-bioc/R/lib/libRblas.so
LAPACK: /home/biocbuild/bbs-3.13-bioc/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] batchelor_1.8.0 scran_1.20.0
[3] scater_1.20.0 ggplot2_3.3.3
[5] scuttle_1.2.0 org.Hs.eg.db_3.13.0
[7] AnnotationDbi_1.54.0 scRNAseq_2.6.0
[9] SingleCellExperiment_1.14.0 SummarizedExperiment_1.22.0
[11] Biobase_2.52.0 GenomicRanges_1.44.0
[13] GenomeInfoDb_1.28.0 IRanges_2.26.0
[15] S4Vectors_0.30.0 BiocGenerics_0.38.0
[17] MatrixGenerics_1.4.0 matrixStats_0.58.0
[19] BiocStyle_2.20.0 rebook_1.2.0
loaded via a namespace (and not attached):
[1] AnnotationHub_3.0.0 BiocFileCache_2.0.0
[3] igraph_1.2.6 lazyeval_0.2.2
[5] BiocParallel_1.26.0 digest_0.6.27
[7] ensembldb_2.16.0 htmltools_0.5.1.1
[9] viridis_0.6.1 fansi_0.4.2
[11] magrittr_2.0.1 memoise_2.0.0
[13] ScaledMatrix_1.0.0 cluster_2.1.2
[15] limma_3.48.0 Biostrings_2.60.0
[17] prettyunits_1.1.1 colorspace_2.0-1
[19] blob_1.2.1 rappdirs_0.3.3
[21] xfun_0.23 dplyr_1.0.6
[23] crayon_1.4.1 RCurl_1.98-1.3
[25] jsonlite_1.7.2 graph_1.70.0
[27] glue_1.4.2 gtable_0.3.0
[29] zlibbioc_1.38.0 XVector_0.32.0
[31] DelayedArray_0.18.0 BiocSingular_1.8.0
[33] scales_1.1.1 edgeR_3.34.0
[35] DBI_1.1.1 Rcpp_1.0.6
[37] viridisLite_0.4.0 xtable_1.8-4
[39] progress_1.2.2 dqrng_0.3.0
[41] bit_4.0.4 rsvd_1.0.5
[43] ResidualMatrix_1.2.0 metapod_1.0.0
[45] httr_1.4.2 dir.expiry_1.0.0
[47] ellipsis_0.3.2 pkgconfig_2.0.3
[49] XML_3.99-0.6 farver_2.1.0
[51] CodeDepends_0.6.5 sass_0.4.0
[53] dbplyr_2.1.1 locfit_1.5-9.4
[55] utf8_1.2.1 tidyselect_1.1.1
[57] labeling_0.4.2 rlang_0.4.11
[59] later_1.2.0 munsell_0.5.0
[61] BiocVersion_3.13.1 tools_4.1.0
[63] cachem_1.0.5 generics_0.1.0
[65] RSQLite_2.2.7 ExperimentHub_2.0.0
[67] evaluate_0.14 stringr_1.4.0
[69] fastmap_1.1.0 yaml_2.2.1
[71] knitr_1.33 bit64_4.0.5
[73] purrr_0.3.4 KEGGREST_1.32.0
[75] AnnotationFilter_1.16.0 sparseMatrixStats_1.4.0
[77] mime_0.10 biomaRt_2.48.0
[79] compiler_4.1.0 beeswarm_0.3.1
[81] filelock_1.0.2 curl_4.3.1
[83] png_0.1-7 interactiveDisplayBase_1.30.0
[85] statmod_1.4.36 tibble_3.1.2
[87] bslib_0.2.5.1 stringi_1.6.2
[89] highr_0.9 GenomicFeatures_1.44.0
[91] bluster_1.2.0 lattice_0.20-44
[93] ProtGenerics_1.24.0 Matrix_1.3-3
[95] vctrs_0.3.8 pillar_1.6.1
[97] lifecycle_1.0.0 BiocManager_1.30.15
[99] jquerylib_0.1.4 BiocNeighbors_1.10.0
[101] cowplot_1.1.1 bitops_1.0-7
[103] irlba_2.3.3 httpuv_1.6.1
[105] rtracklayer_1.52.0 R6_2.5.0
[107] BiocIO_1.2.0 bookdown_0.22
[109] promises_1.2.0.1 gridExtra_2.3
[111] vipor_0.4.5 codetools_0.2-18
[113] assertthat_0.2.1 rjson_0.2.20
[115] withr_2.4.2 GenomicAlignments_1.28.0
[117] Rsamtools_2.8.0 GenomeInfoDbData_1.2.6
[119] hms_1.1.0 grid_4.1.0
[121] beachmat_2.8.0 rmarkdown_2.8
[123] DelayedMatrixStats_1.14.0 Rtsne_0.15
[125] shiny_1.6.0 ggbeeswarm_0.6.0
[127] restfulr_0.0.13 References
Grun, D., M. J. Muraro, J. C. Boisset, K. Wiebrands, A. Lyubimova, G. Dharmadhikari, M. van den Born, et al. 2016. “De Novo Prediction of Stem Cell Identity using Single-Cell Transcriptome Data.” Cell Stem Cell 19 (2): 266–77.